
Статистика базы данных (Database statistics)
1. Снижение производительности базы данных практически всегда связано с некорректным администрированием и/или плохой обработкой транзакций. Статистика базы данных IBExpert извлекает и отображает важную статистическую информацию базы данных, которую можно экспортировать в файлы различных форматов или распечатать. Данный пункт находится в меню Services\Database Statistics.
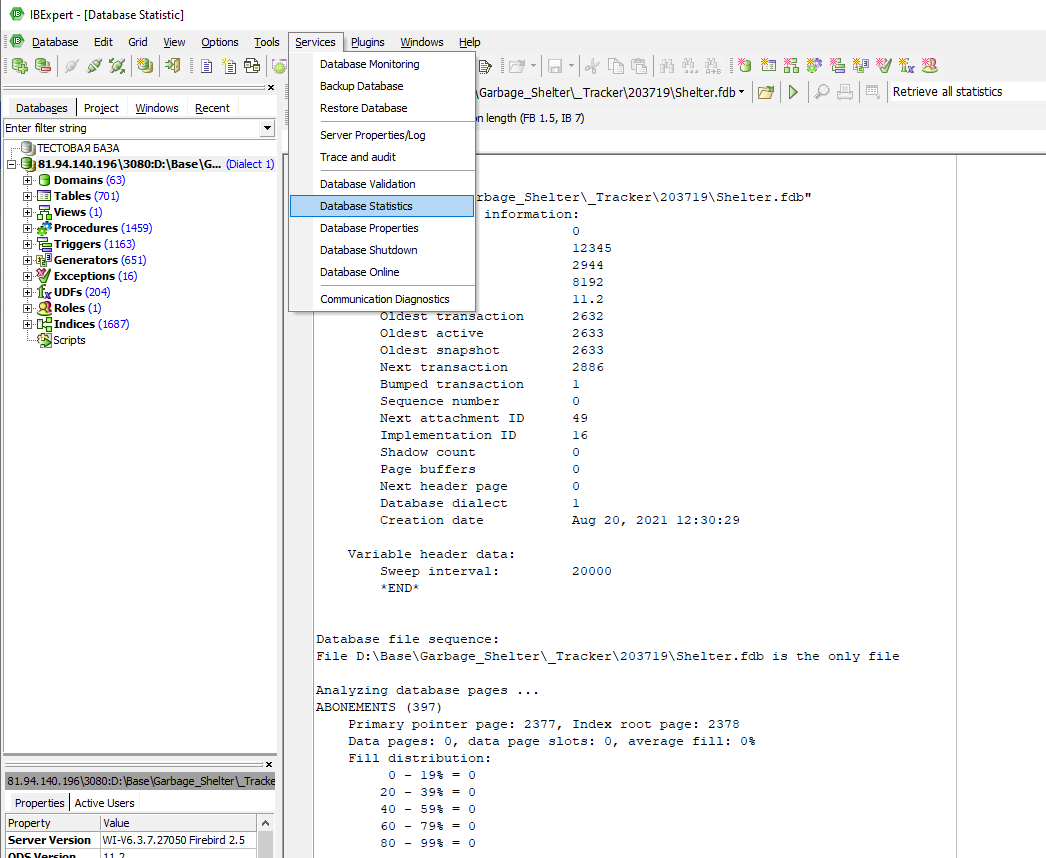 (Рис. 1 - Database Statistics)
(Рис. 1 - Database Statistics)
Статистика базы данных полезна для обнаружения и решения различных проблем с производительностью, например, для определения того, открыта ли где-то старая транзакция, что может замедлить работу базы данных из-за администрирования постоянно растущего числа версий записей. Насколько эффективно заполняется страница данных? Можно ли его улучшить, разделив определенные большие таблицы на несколько меньших? Или для анализа других показателей.
Чтобы сгенерировать текущую статистику базы данных для всей базы данных, сначала нажмите верхнюю левую кнопку, чтобы просмотреть список всех зарегистрированных баз данных:
(Рис. 2 - Employee)
или просто перетащите узел базы данных или один или несколько выбранных узлов таблицы из обозревателя баз данных на страницу текста статистики базы данных для автоматического создания статистики по вашему выбору:
(Рис. 3 - Table Select)
Или откройте существующий файл статистики, чтобы просмотреть и проанализировать статистические записи:
(Рис. 4 - Analyze from file)
При необходимости можно изменить критерий построения статистики, выбрав один из следующих вариантов (Рис. 5):
- Прекратить получение статистики после заголовка страницы
- Прекратить получать статистику по страницам журнала
- Прекратить получение после того, как пользователь проиндексирует статистику
- Прекратить получение статистики после таблиц данных
- Прекратить получение статистики после системных таблиц и индексов
(Рис. 5 - Опции построения статистики)
2. Статистическая сводка базы данных отображается как текст:
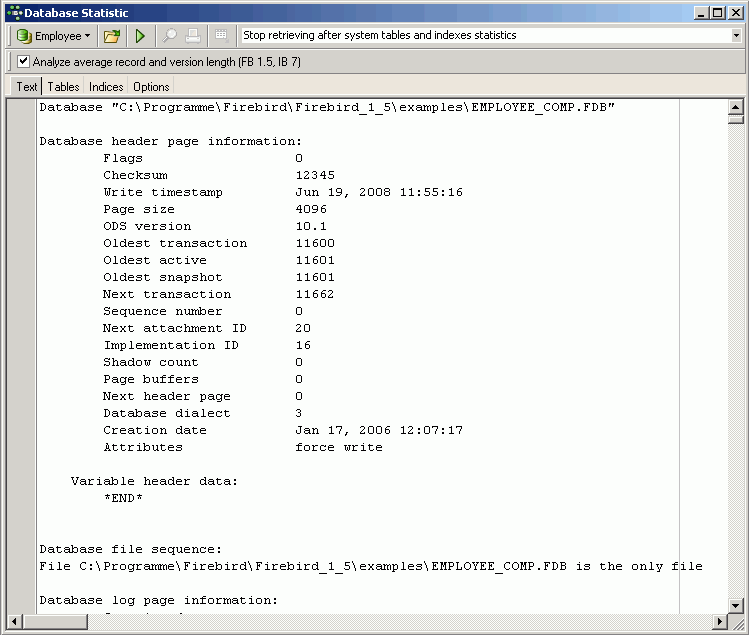
(Рис. 6 - Статистическая сводка)
Текстовая сводка предоставляет определенную информацию из базы данных (Рис. 6), а также статистическую сводку с разбивкой по таблицам (Рис. 8), содержащую информацию, также отображаемую в сводной таблице.
В сводке отображается определенная информация журнала, такая как отметка времени , размер страницы и версия ODS (On-Disk Structure). Затем он перечисляет старейшую транзакцию, старейшая активная транзакция (самая старая транзакция, которая была начата , но еще не совершила или откат), старые снимки (это показывает, где сборщик мусора (Garbage collector) начнет свою работу) и следующую транзакцию . Это статистика, за которой всегда следует следить, поскольку она может указывать на потенциальный источник снижения производительности. Большая разница между самой старой активной транзакцией (OAT), а следующая транзакция указывает, что где-то в базе данных есть открытая транзакция (т. е. транзакция, которая была запущена, но не зафиксирована). Такая проблема может привести к постепенному замедлению работы базы данных по мере того, как сервер администрирует все больше и больше открытых версий, и сборщик мусора не может удалить более старые версии.
Статистика базы данных отображает следующую информацию для всех таблиц в базе данных, как в виде сценария журнала, так и в табличной форме: имя таблицы, расположение, страницы, размер (байты), слоты, заполнение (%) , использование DP (%) и заполнение распространение (оптимальное заполнение страницы - около 80%). Для каждой таблицы статистика индексов включает: глубину , сегменты листа, узлы, среднюю длину данных и распределение заполнения.
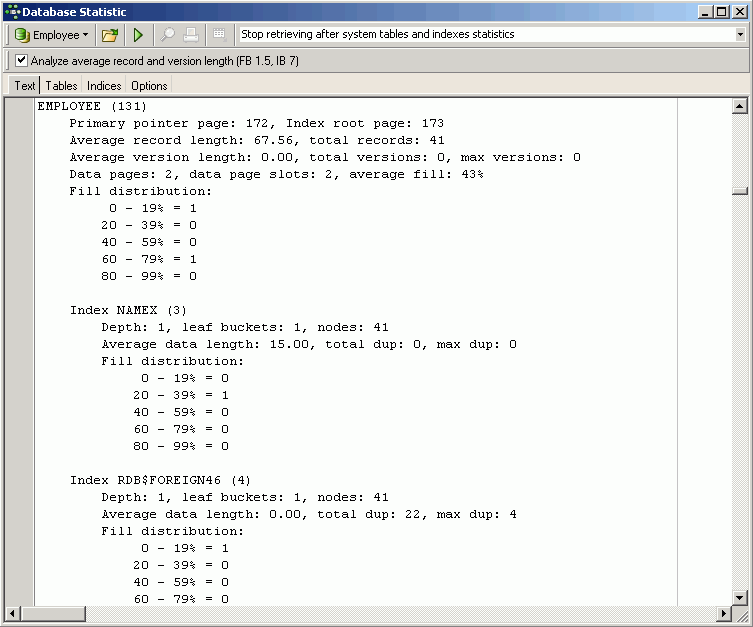
(Рис. 7 - Текстовая статистика)
Страница первичного указателя (Primary Pointer page): На рисунке выше страница первичного указателя (PTR) для таблицы EMPLOYEE имеет номер 172. Она начинается с байта, который равен номеру страницы 172, умноженному на размер страницы . Это своего рода оглавление таблицы EMPLOYEE; он указывает на страницы данных, которые содержат данные таблицы .
Корневая страница индекса (Index root page): та же информация отображается для корневых страниц индекса (IRT) для индексов в этой таблице.
Средняя длина записи (Average record length): показывает, какова средняя длина версий записи данных (в байтах). Когда таблица dBase создается, например, с двумя полями, каждое CHAR (100), средняя длина набора данных всегда будет 200. Firebird / InterBase ®, однако, не сохраняет смежные пустые пространства. Например, поле CHAR (100), содержащее строку длиной 65, за которой следуют 35 пустых пространств, сохраняется Firebird / InterBase ® как строка из 65 плюс 1 пустое пространство, умноженное на 35. Вот почему при импорте данных в Firebird / InterBase ® из другой базы данных, данные иногда после импорта становятся меньше, чем были раньше. (См. Статью о технологии баз данных, Сервер Firebird и VARCHAR., для дополнительной информации.)
Всего записей (Total records): сколько наборов данных содержится в отдельных таблицах.
Средняя длина версии (Average version length): Средняя длина версий записи. После выполнения обновлений вы можете увидеть здесь, сколько байтов в среднем изменилось по сравнению с исходным набором данных.
Всего версий (Total versions): сколько версий записей существует для этой таблицы. Это число всегда должно быть как можно меньше, поскольку оно указывает, сколько версий таблицы хранится Firebird / InterBase ® .
Максимальное количество версий (Max versions): максимальное количество версий для записи. Это указывает на то, что существует одна запись данных с таким количеством различных версий, которую Firebird / InterBase ® должен хранить, потому что где-то в базе данных еще есть одна активная транзакция, что предотвращает удаление старых версий записей.
В этом случае интересно то, что это происходит не только с обрабатываемыми таблицами, но и со всеми таблицами. В режиме повторяемого чтения моментальный снимок всей базы данных создается сразу после запуска транзакции.
Страницы данных (Data pages): сколько страниц данных используется.
Среднее заполнение (Average fill): объем заполнения страницы данных в%.
Распределение заполнения (Fill distribution) : среднее заполнение рассчитывается исходя из того, сколько данных уже содержится на страницах данных. В Firebird / Interbase ® Сервер обычно заполняет страницы до максимума 80%. Свободное место необходимо для хранения предыдущей версии; при обновлении одного из наборов данных, хранящихся на этой странице, новый набор данных может быть сохранен на той же странице, что и исходная версия. Это экономит количество страниц, которые необходимо загрузить, если потребуется вернуться к исходному набору данных.
Распределение заполнения также указывает, является ли заполнение отдельной таблицы аномалией или аналогичные проблемы возникают во всех таблицах.
3. Страница таблиц.
Таблицы перечислены в алфавитном порядке по именам, но, как всегда в IBExpert, их можно перемещать или сортировать по любому из перечисленных критериев, щелкнув соответствующий заголовок столбца . Заголовки столбцов можно перетащить в верхнюю часть страницы таблиц, чтобы отобразить данные, сгруппированные по этому столбцу.
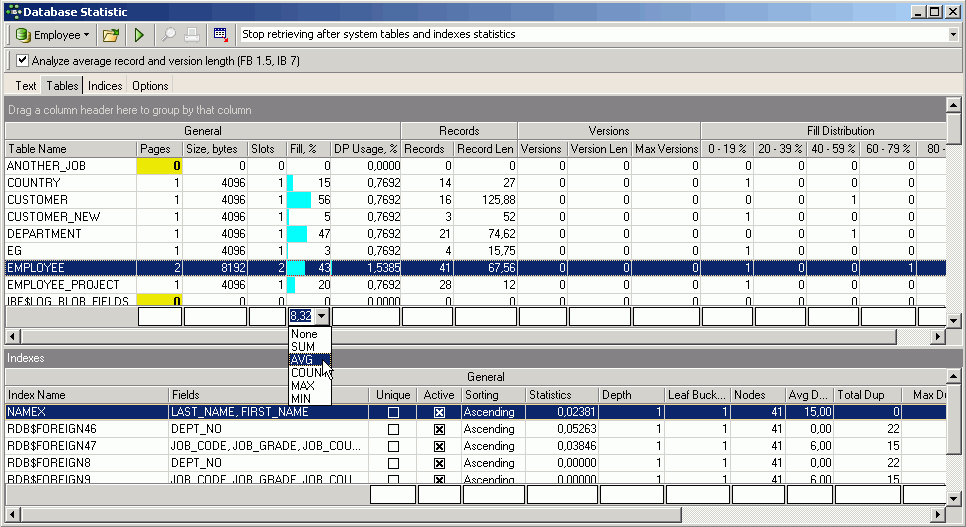
(Рис. 8 - Страница таблиц)
Можно вычислить определенные агрегатные функции для отдельных столбцов (см. Столбец % заполнения на рис. 8).
Сетка таблицы дает хорошие отзывы о заполнении и использовании базы данных в ваших таблицах, например, вы можете быстро обнаружить таблицу с тысячами страниц при 50% -ном заполнении - тратя впустую половину пространства и используя буферы кеша в два раза быстрее, чем если бы страницы были заполнены. Это может быть указание на таблицы с большим количеством вставок и удалений, в этом случае пространство будет использовано повторно. Однако это также могло быть связано с недостаточным размером страницы , например, с размером страницы 4 КБ или 8 КБ и таблицами, в которые, возможно, были добавлены поля в течение определенного периода времени. Если наборы данных настолько велики, что на странице умещается только одна или две записи, остается много места.
Вы также можете обнаружить таблицу, которая, хотя и охватывает n страниц данных с использованием всего x байтов, с y количеством записей, но со средней длиной записи 0. В столбцах « Версии» отображается такое же количество записей со средней длиной записи, равной 0 байтов. Это означает, что таблица была удалена и больше не содержит данных. Однако версии записей по-прежнему должны поддерживаться для старых открытых транзакций.
Под сеткой таблицы индексная сетка отображает статистику для всех индексов выбранной таблицы. Для индексов отображается следующая информация: Имя индекса, Поля, Уникальный, Активный, Порядок сортировки, Статистика, Глубина, Конечные сегменты, Узлы , Средняя длина данных, Общее дублирование и Распределение заполнения. Дополнительную информацию можно найти на странице индексов.
Эта информация в табличной форме может быть экспортирована для сохранения информации в файл или распечатана.
Для получения дополнительной информации о том, как использовать статистику базы данных для максимизации производительности базы данных, обратитесь к главе «Администрирование Firebird с использованием IBExpert» , «Использование статистики базы данных IBExpert» .
4. Страница индексов.
Помимо сводной информации, отображаемой на странице " Таблицы", страница " Индексы" позволяет вам глубоко проанализировать все индексы вашей базы данных . Используя раскрывающийся список, вы можете указать, какие типы индексов вы хотите просмотреть:
- Все индексы (All indices)
- Плохие показатели (Bad indices)
- Бесполезные индексы (Useless indices)
- Слишком глубокие индексы (Too deep indices)
- Активные индексы (Active indices)
- Неактивные индексы (Inactive indices)
- Уникальные индексы (Unique indices)
- Неуникальные индексы (Non-unique indices)
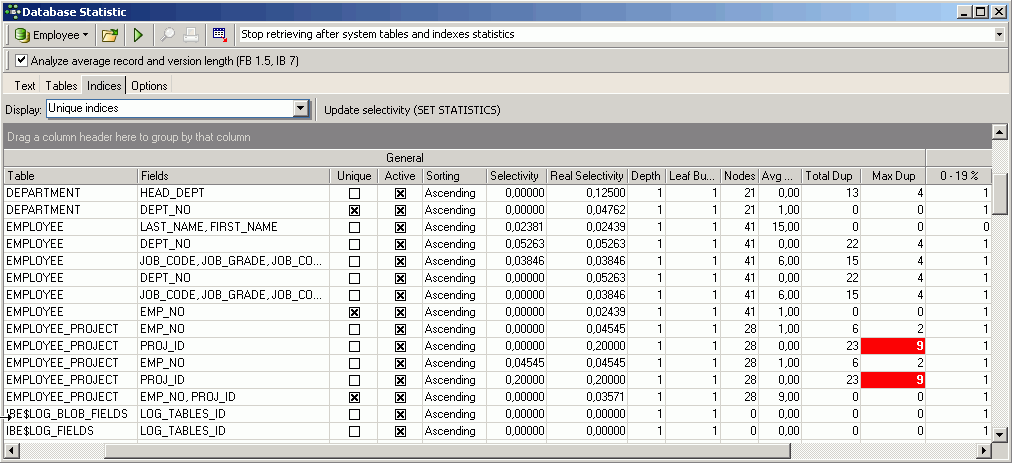
(Рис. 9 - Уникальные индексы)
Индексы перечислены по таблице и полю, но, как всегда в IBExpert, их можно перемещать или сортировать по любому из перечисленных критериев, щелкнув соответствующий заголовок столбца. Заголовки столбцов можно перетащить в верхнюю часть страницы индексов, чтобы отобразить данные, сгруппированные по этому столбцу. Вы можете сразу определить тип индекса (Уникальный , Активный , По возрастанию или По убыванию).
В столбце Selectivity отображается фактическая селективность, которая принимается во внимание в Firebird / Interbase®сервер, при работе, как лучше обработать запрос. В столбце Real Selectivity отображается уровень селективности, которого можно было бы достичь, если бы индекс был пересчитан. Если вы обнаружите расхождения в этих двух столбцах, нажмите кнопку Update Selectivity (Set Statistics) , чтобы пересчитать избирательность. Эти несоответствия возникают из-за того, что селективность вычисляется только во время создания или когда используется пункт меню IBExpert Recompute selectivity of all indices или Recompute all (см. рис. 10).
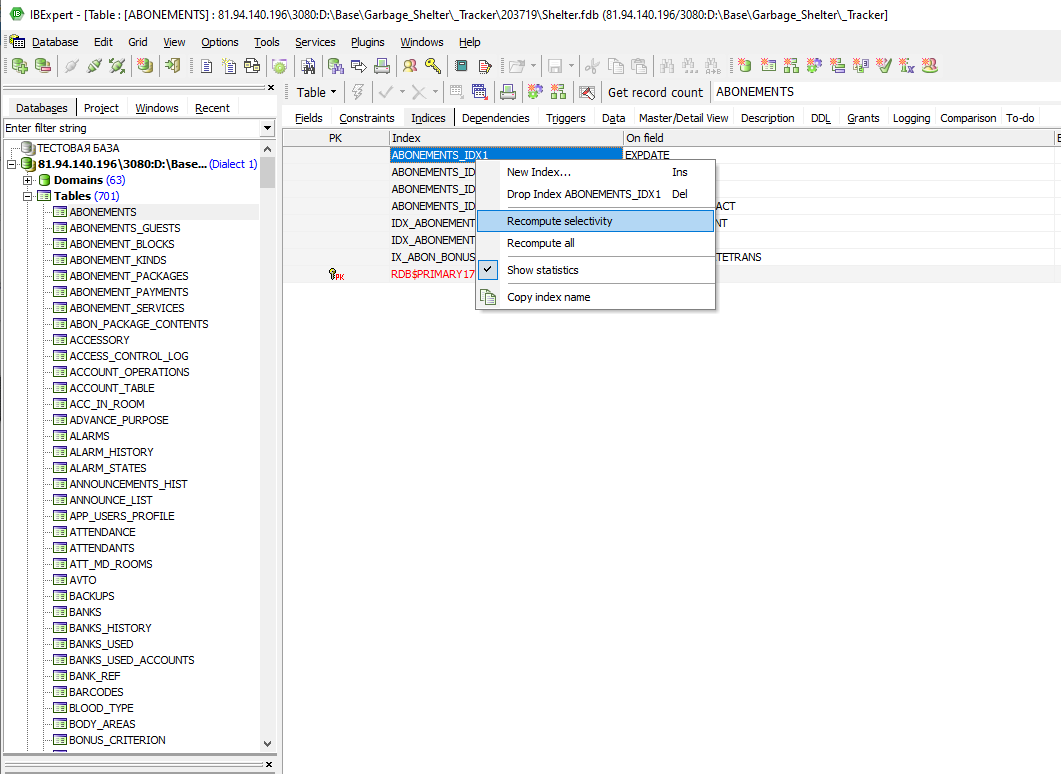
(Рис. 10 - Recompute selectivity/recompute all)
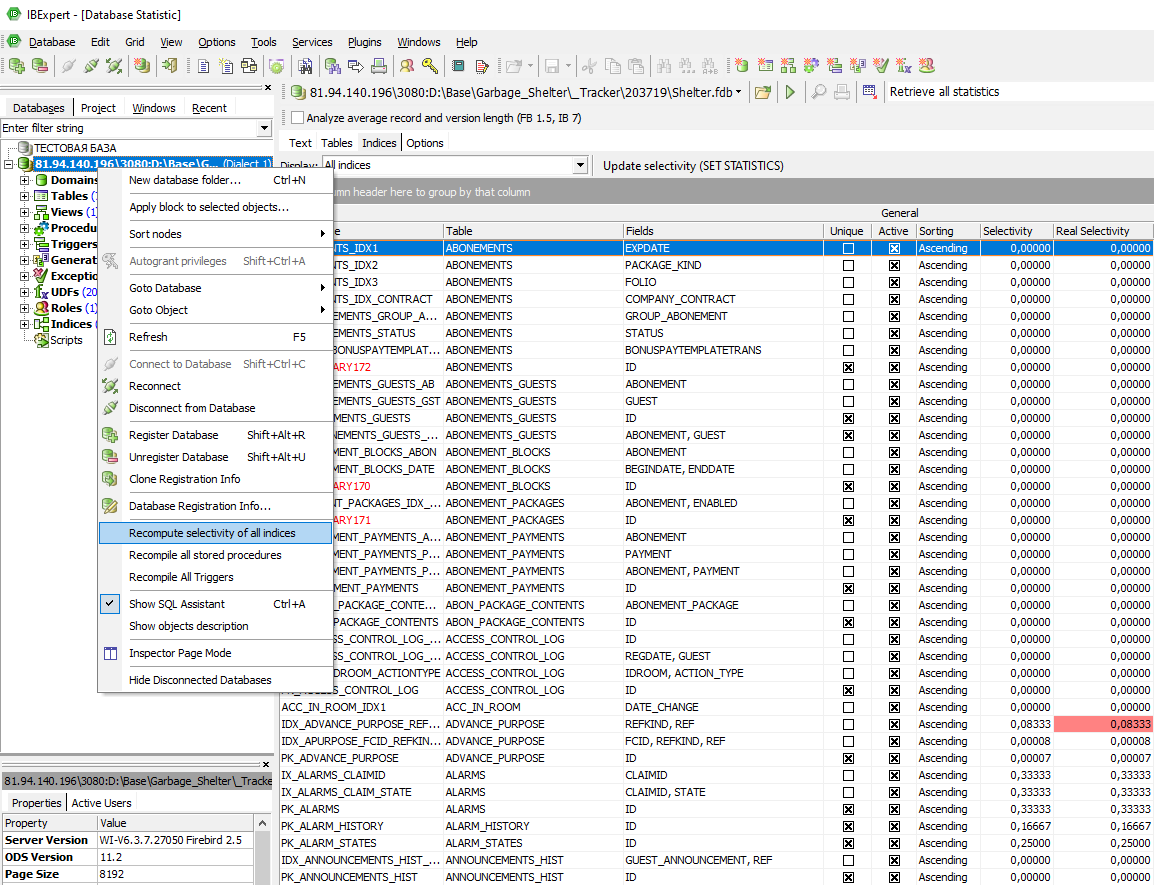
(Рис. 11 - Recompute selectivity of all indices)
SET STATISTIC INDEX {INDEX_NAME}
Команда SET STATISTIC INDEX {INDEX_NAME} может использоваться в редакторе SQL (SQL Editor) для пересчета отдельных индексов.
Это автоматически выполняется во время резервного копирования и восстановления базы данных, поскольку сохраняется не индекс, а его определение, и поэтому индекс восстанавливается при восстановлении базы данных.
Первое, что делает оптимизатор при получении запроса, - это подготавливает выполнение. Он принимает решения относительно индексов исключительно на основании их избирательности. Плохие индексы - это те, которые Firebird/InterBase®считает плохими. Может быть несколько причин, по которым Оптимизатор может считать определенный индекс плохим :
- Оптимизатор использует индексы с избирательностью <0,01 только при отсутствии других доступных индексов.
- Такой индекс вызывает очень медленную сборку мусора в старых версиях Firebird и InterBase®. Эта проблема была решена , поскольку InterBase®7.1/7.5 и Firebird 2.0.
- Индекс заставляет процесс восстановления быть очень медленным, и он создается очень медленно (CREATE / ALTER INDEX ACTIVE). Это связано с тем, что цепочка номеров записей велика для одного индексного ключа.
- Если индекс используется в предложении WHERE, использование памяти будет зависеть от искомого значения (размера битовой маски). Поскольку цепочка записей может быть большой (много дубликатов ключей), потребление памяти также будет большим.
- Если индекс используется в ORDER BY и имеется много дубликатов, в основном в нижних значениях ключа (в зависимости от порядка сортировки индекса), будет много чтений страницы индекса, что замедлит выполнение запроса.
Худший случай для индекса - это когда значение в столбце Uniques = 1, то есть, все значения для индексированного столбца одинаковы. Эти индексы перечислены как бесполезные индексы. Конечно, для вашего приложения может возникнуть ситуация, когда такой индекс подходит. Например, если записи имеют флаг «архивировать» в столбце, и ваше приложение выполняет поиск по индексу в этом столбце только для текущих, а не архивированных данных.
Обычно плохие и бесполезные индексы должны быть проверены и, если они не очень важны для вашего приложения (например, если вы не используете его для поиска ключей, имеющих меньше дубликатов, чем другие ключи), удалить. Однако это непросто сделать, если такой индекс создается внешним ключом, потому что вы можете отбросить его, только отбросив внешний ключ. Однако удаление внешнего ключа отключит соответствующее ограничение проверки, что может быть неприемлемым. Возможна замена внешнего ключа триггерами, но есть некоторые ограничения. Внешние ключи управляют отношениями записей с помощью индекса, и индекс видит все ключи для всех записей независимо от состояния транзакции. Однако триггер работает только в контексте транзакции клиента. Таким образом, при замене внешних ключей на триггеры вы должны быть уверены, что, во-первых, записи не будут удалены из главной таблицы или удалены в режиме snapshot table reserving, а во-вторых, убедитесь, что столбец, используемый первичным ключом в главной таблице, никогда не будет изменен. Вы можете ограничить это с помощью триггера перед обновлением .
Если вы соблюдаете эти условия, вы можете отбросить конкретный внешний ключ.
В следующем столбце отображается глубина индекса. Например, глубина индекса 2 означает, что Firebird/InterBase® необходимо выполнить два шага для получения результата. Обычно значение не должно быть больше трех. В этом случае может помочь резервное копирование и восстановление базы данных.
5. Страница опций.
Есть возможность автоматически анализировать статистику таблиц/индексов и выделять возможные проблемные таблицы/индексы. Эта функция основана на функциональности IBEBlock, поэтому ее можно полностью настроить.
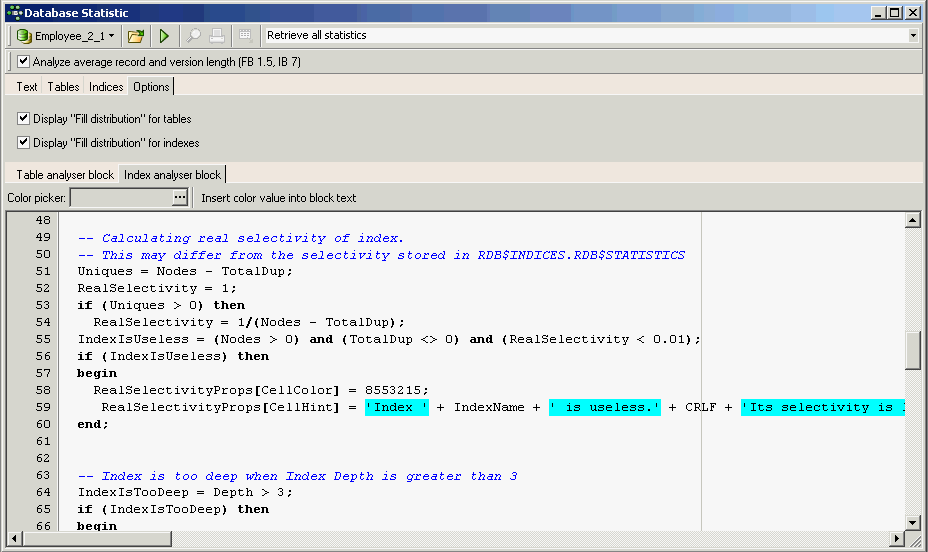
(Рис. 12 - Страница опций)